
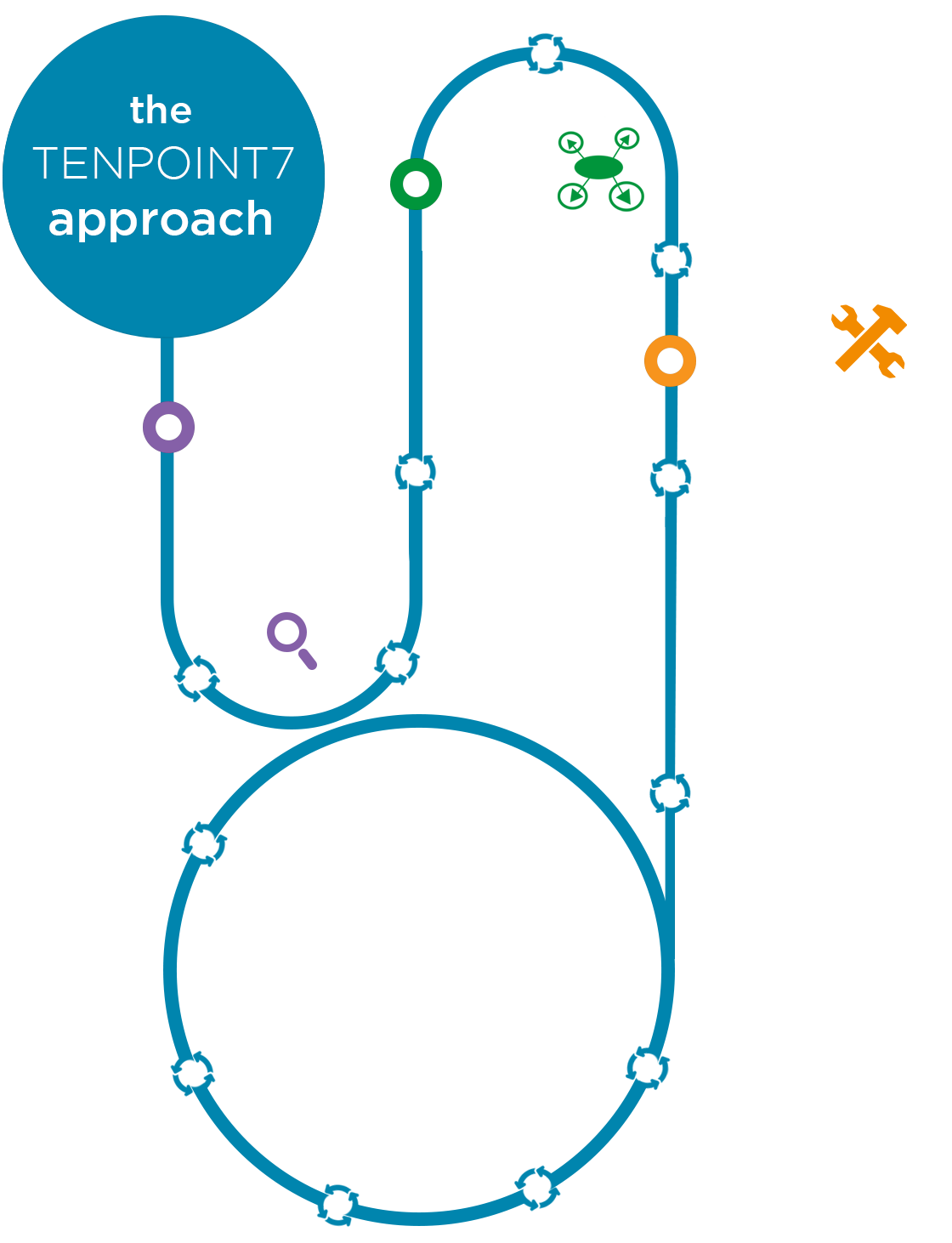
Many organizations have started to believe in the game-changing power that data science can deliver to their businesses. Yet the inherent complexity and risk of starting such initiatives can be daunting to some organizations. At TenPoint7, we embrace these complexities and risks through our foundational data science methodology. Our highly iterative and collaborative methodology provides flexibility in the adoption of the appropriate advanced analytical methods and tools/technologies that deliver those impactful outcomes that data science promises to deliver.
Discover
Business
Understanding
Solution
Measurement
Plan
Data
Exploration
Build
Data
Acquisition
Scientific
Modeling
Model
Evaluation
Deployment
Manage
Maintain
At Tenpoint7, Agile development methodologies (especially Scrum and Extreme Programming framework) are being applied to solve the problem. The Agile iterative process help us to shorten development cycles and speed up business request clarification. Therefore, Agile allow us to deliver value in weeks–or even days –rather than months, years.
Business Understanding
- Define business problem
- Discover business success criteria
Regardless of size, we initiate every project with assessing the needs of the business. Problem definition is especially hard with data science initiatives in part due to stakeholder expectations. Working in close collaboration with client business and technical experts, we play a critical role at this stage by defining the problem, identifying use cases, asking relevant questions across key stakeholder groups, uncovering project constraints and subsequently establishing objective and measurable criteria that will determine the successful outcome of the project.
Solution Measurement
- Determine scientific success metrics
After establishing business objectives of the project, we translate the business problem to one of analytics with specific measurable outcomes, such as predicting the number of units that will be purchased given a mix of demographic and historical transactional data. Business success criteria are also translated into its corresponding solution metrics such as precision, recall, performance while understanding the trade-offs between each. While conducting such a translation exercise, we also start to express the problem in the context of statistical and/or machine-learning techniques specifying the type of data science problem that needs to be solved such as classification, clustering or regression.
Data Exploration
- Assess tools, data eco-system, architecture
- Determine data requirements
- Gauge data quality
- Formulate hypotheses
With the analytical goals of the project identified, we start to use descriptive statistics and visualization/plotting techniques to help us understand data content and requirements, identify key attributes, assess overall data quality and discover preliminary insights. These occur in tandem, as the team gets familiar with the overall data architecture. Typical activities include conducting volumetric analysis of data, understanding and computing simple statistics on data attributes, interviewing client domain experts and data engineers, and uncovering data quality issues such as missing attributes and format inconsistencies. The outcome of this phase typically results in the formation of initial solution hypotheses that influences the remainder of the project.
Data Acquisition
- Identify data sources
- Ingest & clean data
- Conduct data transformations
At this stage, we’re ready to collect and integrate data (structured/unstructured/semi-structured) across relevant data sources that could be combinations of internal client data stores, silos as well as external sites relevant to the problem domain. Subsequently, data cleaning activities are conducted including correction/removal of noise, and dealing with special attribute values. Additionally, constructive data preparation and transformation activities occur here that typically include feature engineering to derive new variables, applying dimension reduction techniques such as Principal Component Analysis (PCA), data formatting, single-attribute transformation as well as enriching the set of predictors. This is a highly iterative process where identified data issues sometimes require revisiting data requirements and acquiring additional data.
Scientific Modeling
- Define test design
- Build models
- Evaluate fit of models
- Scale model to production data
Most scientific model building requires a well-defined plan to test the quality and validity of the model. We usually start this phase by evaluating and selecting the appropriate training-and-test regimen, e.g. multi-fold-cross-validation v/s bootstrap method partitioning the prepared data set into train and test sets when needed.
A highly iterative process then follows of selecting, testing and evaluating fit across appropriate model classes –decision trees v/s neural nets v/s regression, etc. to name just a few.
Specific assumptions about the data are made and documented for each technique selected, along with listing of all model parameters and chosen values. Technical assessment of models follows where results are evaluated against the solution metrics in consultation with business experts. Where applicable, models are also tested on test infrastructure to assess performance on larger production scale data.
Model Evaluation
- Assess model results
- Identify model enhancements/refinements
With the appropriate generated model/s selected, the next phase assesses the degree to which the model/s meet the (business) success criteria of the project. This typically involves an evaluation and interpretation of the scientific diagnostic measures of the model/s against the business project objectives with project sponsors and functional experts. Evaluation results are compared and a candidate model is considered for production deployment. Outcomes of this phase also include identifying any improvements to the model that will need to be triaged for future releases.
Deployment
- Assist with deployment activities
- Determine monitoring & maintenance plan
- Conduct knowledge transfer
At this phase, we team with client IT/Data Engineering and provide support in deployment activities, including providing assistance with creating deployment plans and conducting knowledge transfer sessions with support staff. Where relevant, monitoring and maintenance plans are also created addressing critical things such as how accuracy and performance of the model will be monitored, and identifying criteria that would question accuracy of model output in the future e.g. new data, change in business objectives, and others.
Maintain
- Conduct project retrospective
- Support ongoing model monitoring & maintenance
Post model deployment, we ensure that project outcomes and other aspects are shared and discussed with project stakeholders and sponsors. As needed, topics such as project management process, model performance, project execution challenges, costs and implementation plans are reviewed along with plans for future improvements are also discussed. Through our DataOps offering, we also provide ongoing support to clients in analyzing model accuracy and proposing performance refinements in lieu of constantly changing business and deployment environments. This activity is often overlooked yet can yield significant additional benefits.
Check out our approach to Business Intelligence.